Esta versión del capítulo fue traducida de manera automática utilizando IA. El capítulo aún no ha sido revisado por un humano.
Este capítulo está basado en los tutoriales de netdiffuseR de 2018 y 2019 en la conferencia Sunbelt. El código fuente de los tutoriales, enseñados por Thomas W. Valente y George G. Vega Yon (autor de este libro), está disponible aquí.
Difusión de innovaciones en redes
Redes de difusión
Explica cómo las nuevas ideas y prácticas (innovaciones) se extienden dentro y entre comunidades.
Aunque muchos factores han demostrado influir en la difusión (Espaciales, Económicos, Culturales, Biológicos, etc.), las Redes Sociales son prominentes.
Hay muchos componentes en el modelo de red de difusión, incluyendo exposiciones de red, umbrales, infectividad, susceptibilidad, tasas de riesgo, tasas de difusión (modelo bass), agrupamiento (I de Moran), y así sucesivamente.
Umbrales
Uno de los conceptos canónicos es el umbral de red. Los umbrales de red (Valente, 1995; 1996), \tau, se definen como la proporción requerida o número de vecinos que te llevan a adoptar un comportamiento particular (innovación), a=1. En términos (muy) generales
Donde E_i es la exposición de i a la innovación y \mathbf{X} es la matriz de adyacencia (la red).
Esto puede ser generalizado y extendido para incluir covariables y otros esquemas de ponderación de red (de eso se trata netdiffuseR).
El paquete de R netdiffuseR
Visión general
netdiffuseR es un paquete de R que:
Está diseñado para Visualizar, Analizar, y simular datos de difusión de red (en general).
Depende de algunos paquetes bastante populares:
RcppArmadillo: Así que es rápido,
Matrix: Así que es grande,
statnet e igraph: Así que no es desde cero
Puede manejar grafos grandes, ej., una matriz de adyacencia con más de 4 mil millones de elementos (PR para RcppArmadillo)
Ya está en CRAN con ~6,000 descargas desde su primera versión, Feb 2016,
Muchas características para hacer fácil leer datos de red (dinámicos), haciéndolo un compañero de otros paquetes de redes.
Conjuntos de datos
netdiffuseR tiene los tres conjuntos de datos clásicos de Redes de Difusión:
medInnovationsDiffNet Doctores y la innovación de Tetraciclina (1955).
brfarmersDiffNet Agricultores brasileños y la innovación de Semilla de Maíz Híbrido (1966).
kfamilyDiffNet Mujeres coreanas y métodos de Planificación Familiar (1973).
brfarmersDiffNet
Dynamic network of class -diffnet-
Name : Brazilian Farmers
Behavior : Adoption of Hybrid Corn Seeds
# of nodes : 692 (1001, 1002, 1004, 1005, 1007, 1009, 1010, 1020, ...)
# of time periods : 21 (1946 - 1966)
Type : directed
Num of behaviors : 1
Final prevalence : 1.00
Static attributes : village, idold, age, liveout, visits, contact, coo... (146)
Dynamic attributes : -
medInnovationsDiffNet
Dynamic network of class -diffnet-
Name : Medical Innovation
Behavior : Adoption of Tetracycline
# of nodes : 125 (1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, ...)
# of time periods : 18 (1 - 18)
Type : directed
Num of behaviors : 1
Final prevalence : 1.00
Static attributes : city, detail, meet, coll, attend, proage, length, ... (58)
Dynamic attributes : -
kfamilyDiffNet
Dynamic network of class -diffnet-
Name : Korean Family Planning
Behavior : Family Planning Methods
# of nodes : 1047 (10002, 10003, 10005, 10007, 10010, 10011, 10012, 10014, ...)
# of time periods : 11 (1 - 11)
Type : directed
Num of behaviors : 1
Final prevalence : 1.00
Static attributes : village, recno1, studno1, area1, id1, nmage1, nmag... (430)
Dynamic attributes : -
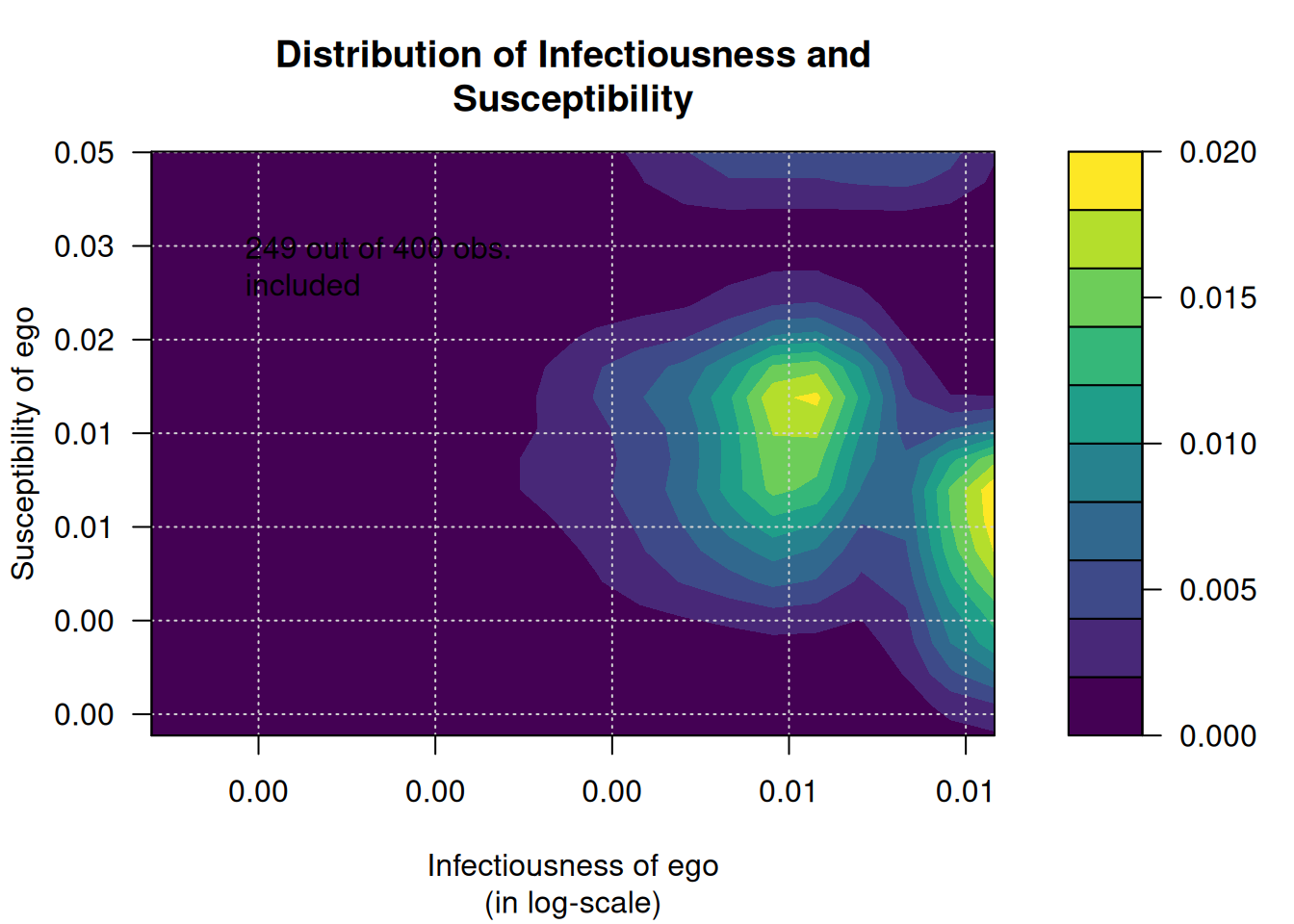
Warning in plot_infectsuscep.list(graph$graph, graph$toa, t0, normalize, : When
applying logscale some observations are missing.
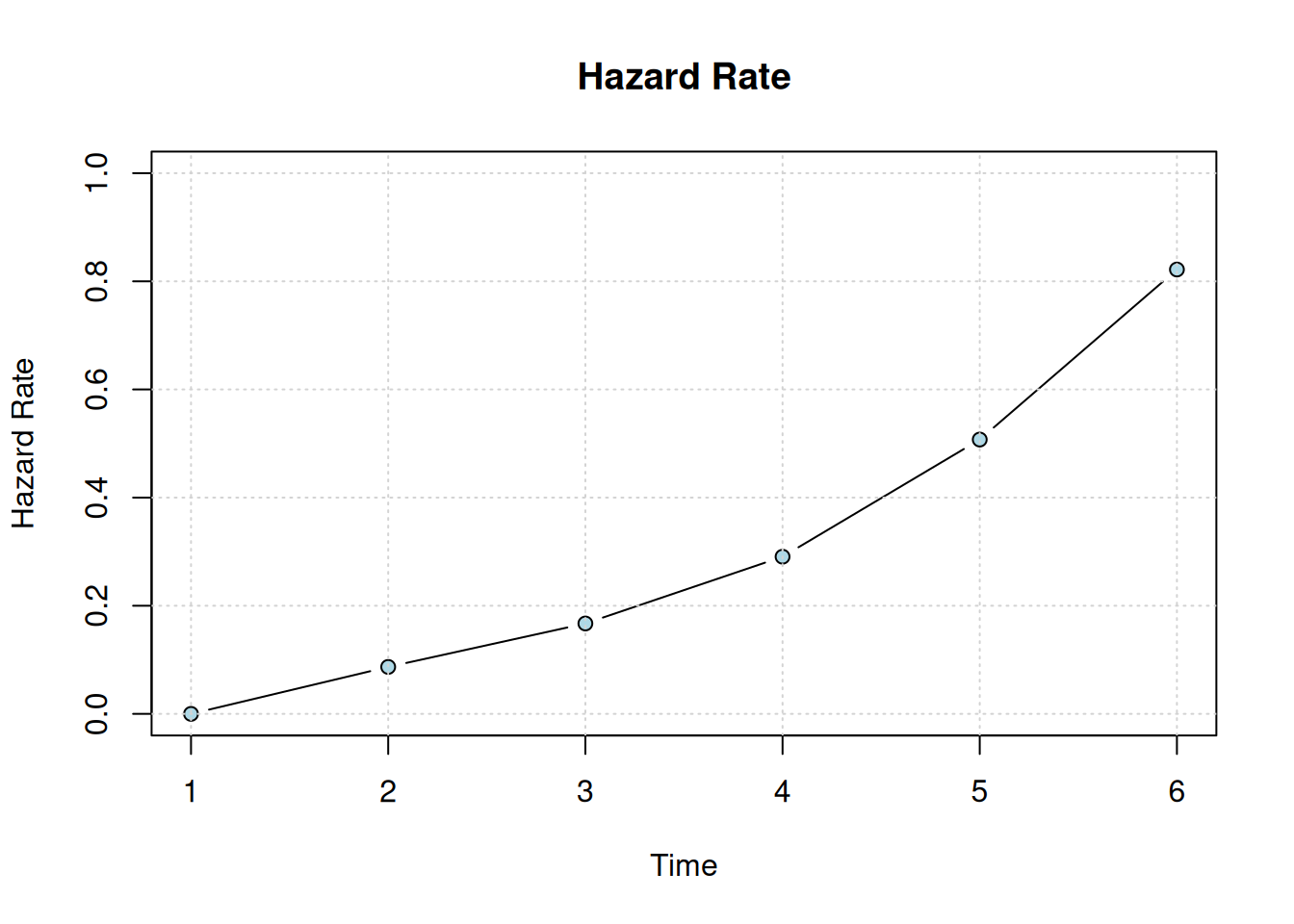
plot_hazard(x)
Problemas
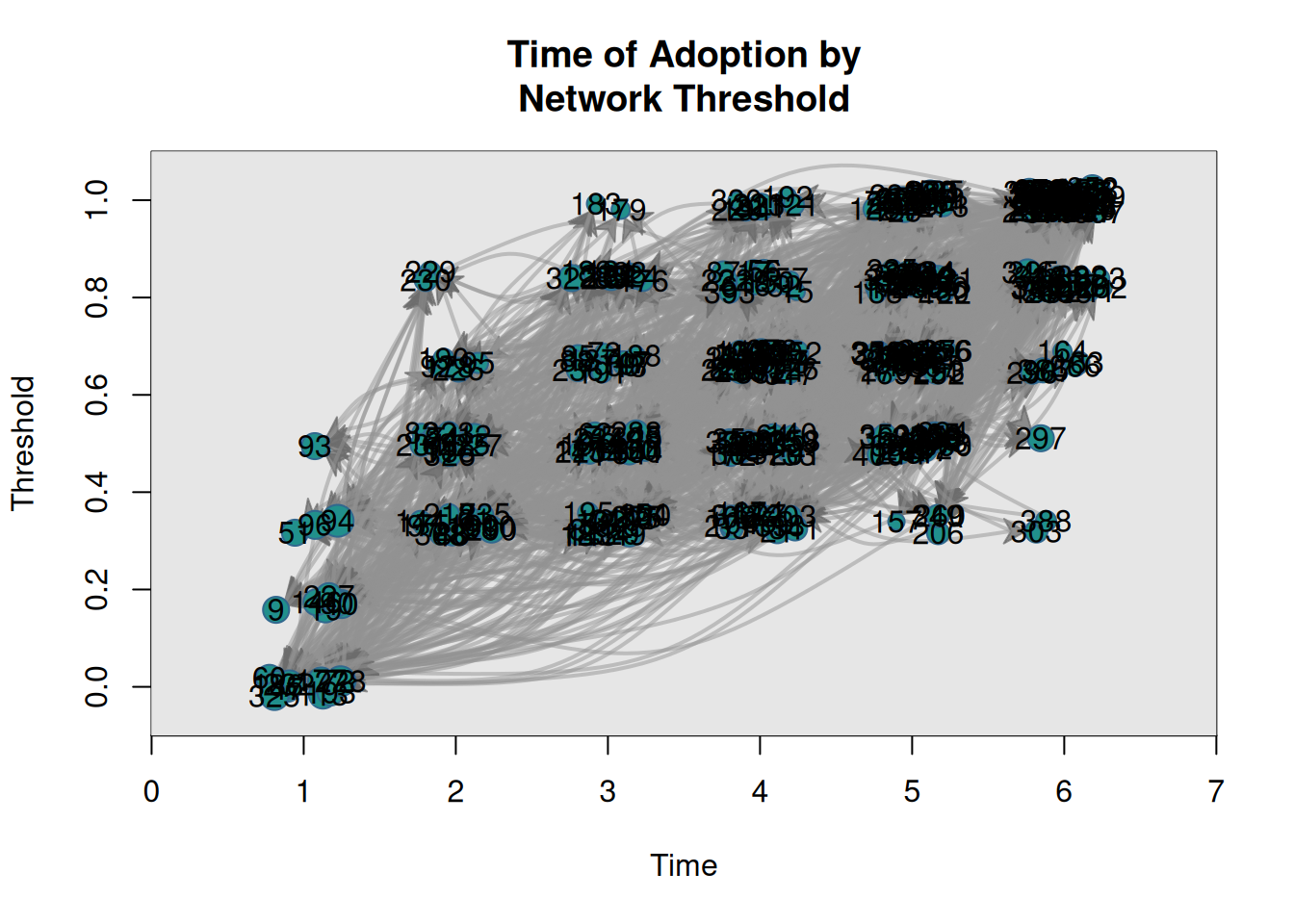
Usando el objeto diffnet en intro.rda, usa la función plot_threshold especificando formas y colores según las variables ItrustMyFriends y Age. ¿Ves algún patrón?
Simulación de procesos de difusión
Antes de comenzar, una revisión de los conceptos que usaremos aquí
Exposición: Proporción/número de vecinos que han adoptado una innovación en cada punto en el tiempo.
Umbral: La proporción/número de tus vecinos que habían adoptado en o un período de tiempo antes de que ego (el individuo focal) adoptara.
Infectividad: Cuánto la adopción de i afecta a sus alters.
Susceptibilidad: Cuánto la adopción de los alters de i la afecta.
Equivalencia estructural: Qué tan similar es i a j en términos de posición en la red.
Simulando redes de difusión
Simularemos una red de difusión con los siguientes parámetros:
Tendrá 1,000 vértices,
Abarcará 20 períodos de tiempo,
Los adoptadores iniciales (semillas) serán seleccionados al azar,
Las semillas serán un 10% de la red,
El grafo (red) será mundo pequeño,
Usará el algoritmo WS con p=.2 (probabilidad de reconexión).
Los niveles de umbral serán distribuidos uniformemente entre [0.3, 0.7]
Para generar esta red de difusión, podemos usar la función rdiffnet incluida en el paquete:
# Setting the seed for the RNGset.seed(1213)# Generating a random diffusion networknet <-rdiffnet(n =1e3, # 1.t =20, # 2.seed.nodes ="random", # 3.seed.p.adopt = .1, # 4.seed.graph ="small-world", # 5.rgraph.args =list(p=.2), # 6.threshold.dist =function(x) runif(1, .3, .7) # 7. )
La función rdiffnet genera redes de difusión aleatorias. Características principales:
Simulando grafo aleatorio o usando el tuyo propio,
Estableciendo niveles de umbral por nodo,
Reconexión de red a lo largo de la simulación, y
Estableciendo los nodos semilla.
El algoritmo de simulación es el siguiente:
Si se requiere, se crea un grafo de referencia,
Se establece el conjunto de adoptadores iniciales y distribución de umbral,
Se crea el conjunto de t redes (si se requiere), y
La simulación comienza en t=2, asignando adoptadores basándose en exposiciones y umbrales:
Para cada i \in N, si su exposición en t-1 es mayor que su umbral, entonces adopta, de otra manera, continúa sin cambio.
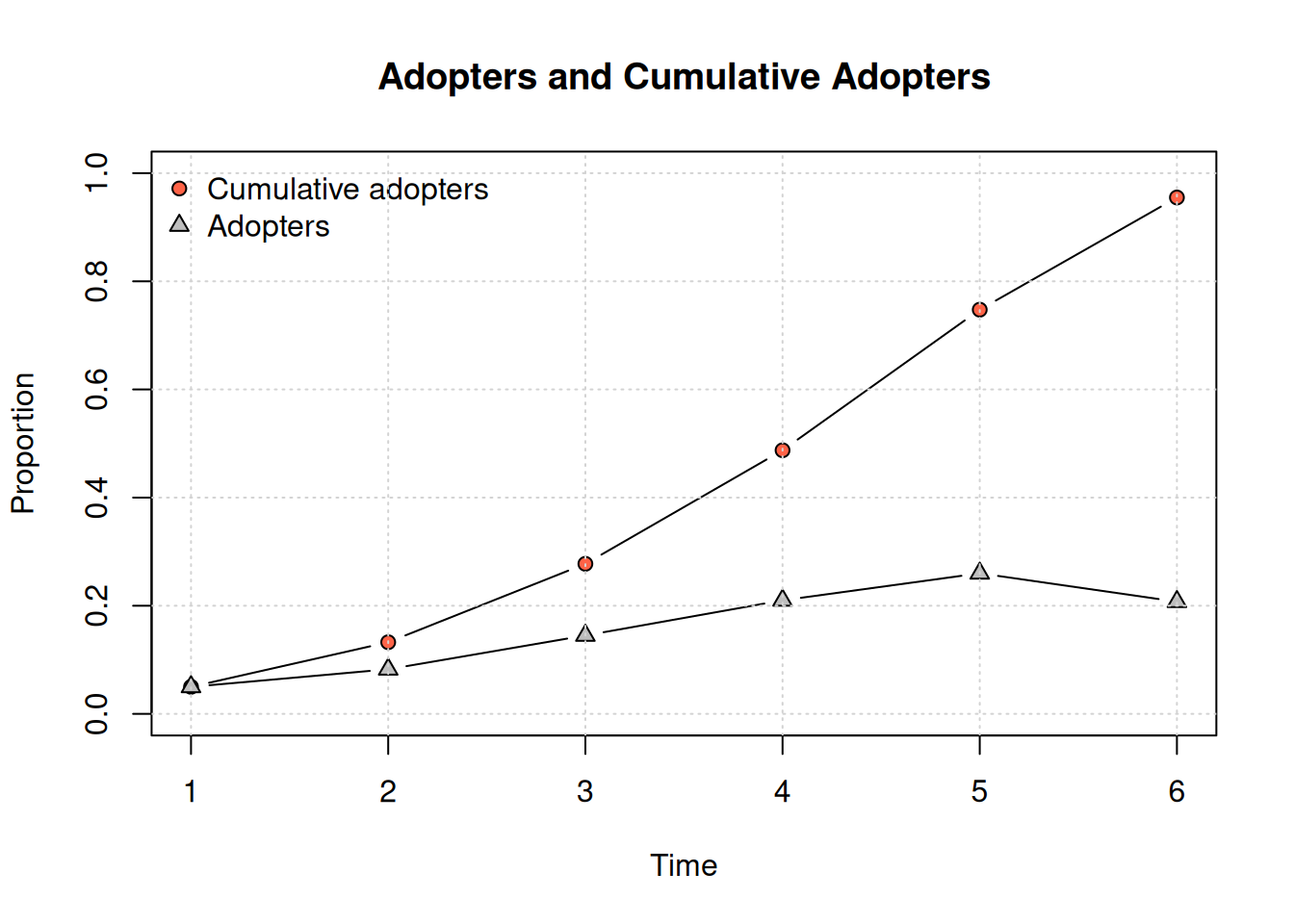
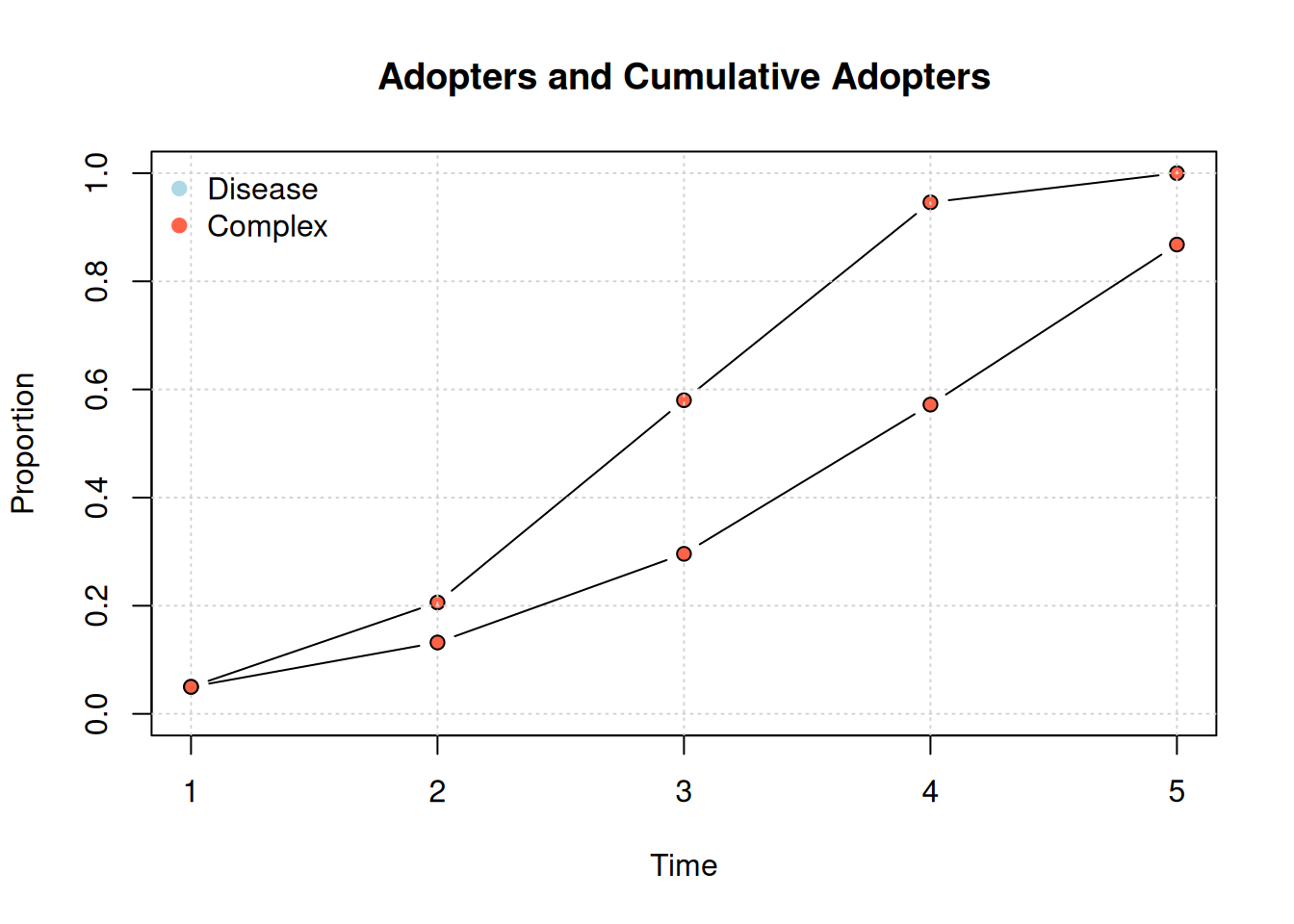
Diffusion network summary statistics
Name : A diffusion network
Behavior : Random contagion
-----------------------------------------------------------------------------
Period Adopters Cum Adopt. (%) Hazard Rate Density Moran's I (sd)
-------- ---------- ---------------- ------------- --------- ----------------
1 25 25 (0.05) - 0.01 -0.00 (0.00)
2 78 103 (0.21) 0.16 0.01 0.01 (0.00) ***
3 187 290 (0.58) 0.47 0.01 0.01 (0.00) ***
4 183 473 (0.95) 0.87 0.01 0.01 (0.00) ***
5 27 500 (1.00) 1.00 0.01 -
-----------------------------------------------------------------------------
Left censoring : 0.05 (25)
Right centoring : 0.00 (0)
# of nodes : 500
Moran's I was computed on contemporaneous autocorrelation using 1/geodesic
values. Significane levels *** <= .01, ** <= .05, * <= .1.
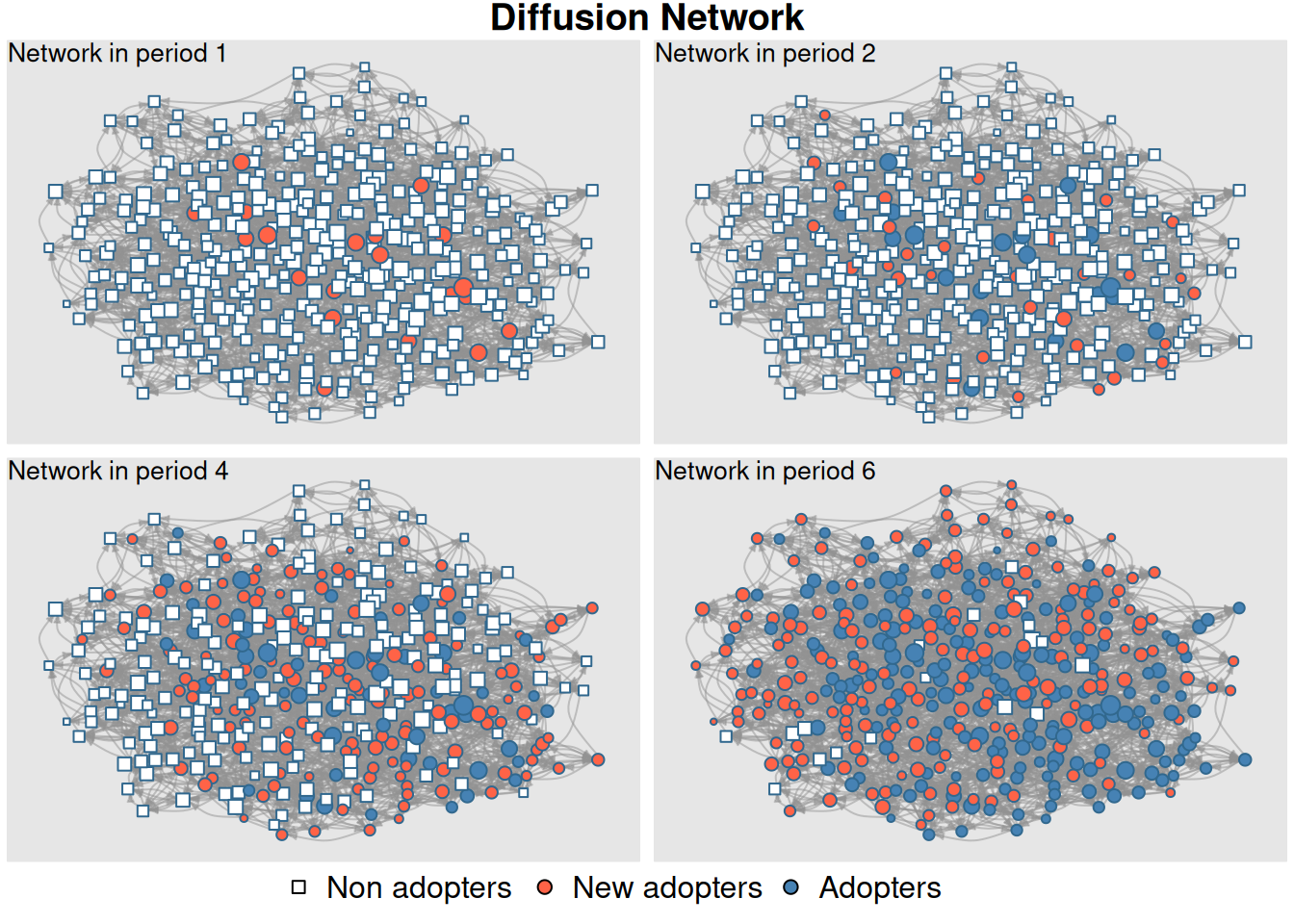
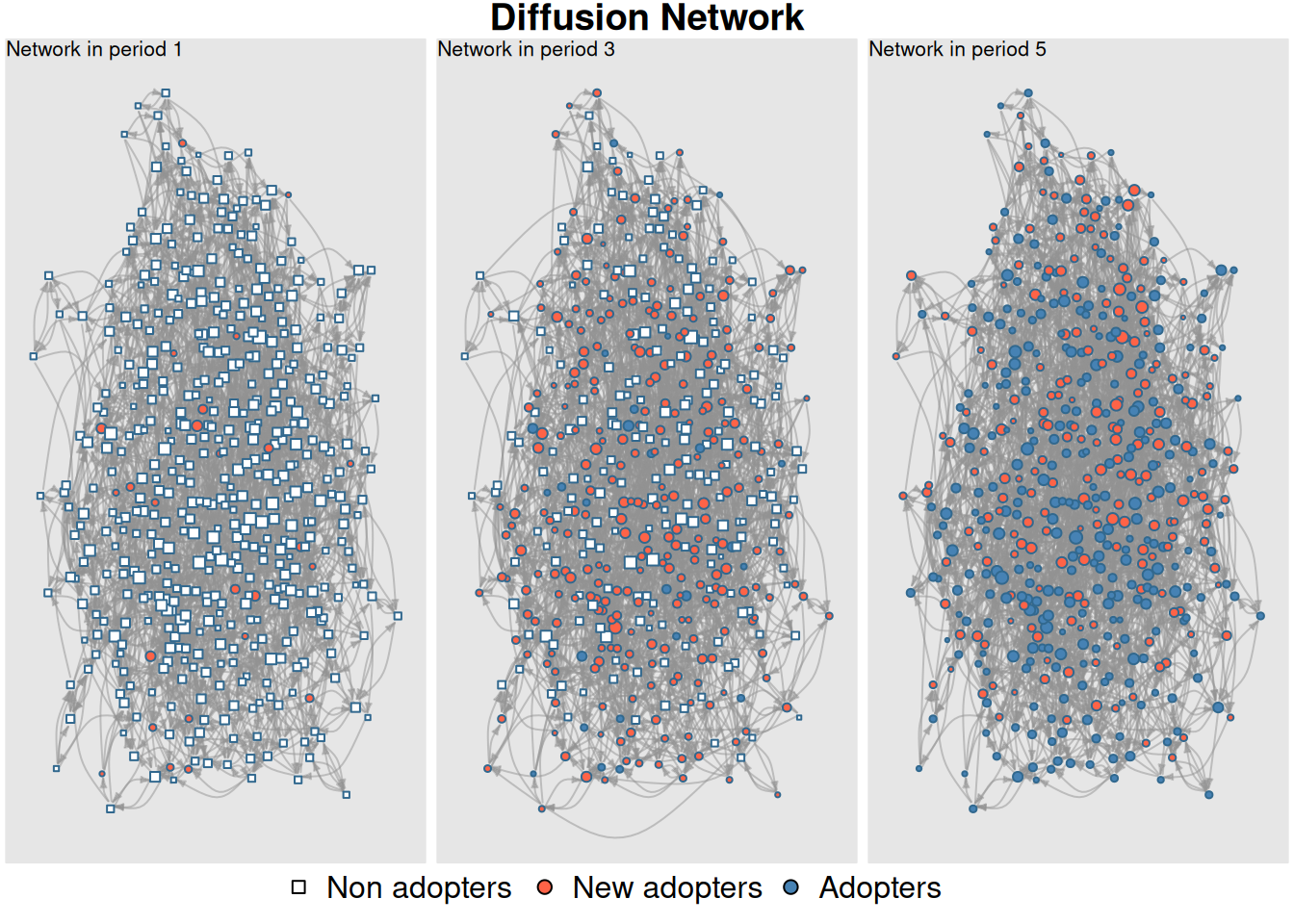
plot_diffnet(diffnet_rumor, slices =c(1, 3, 5))
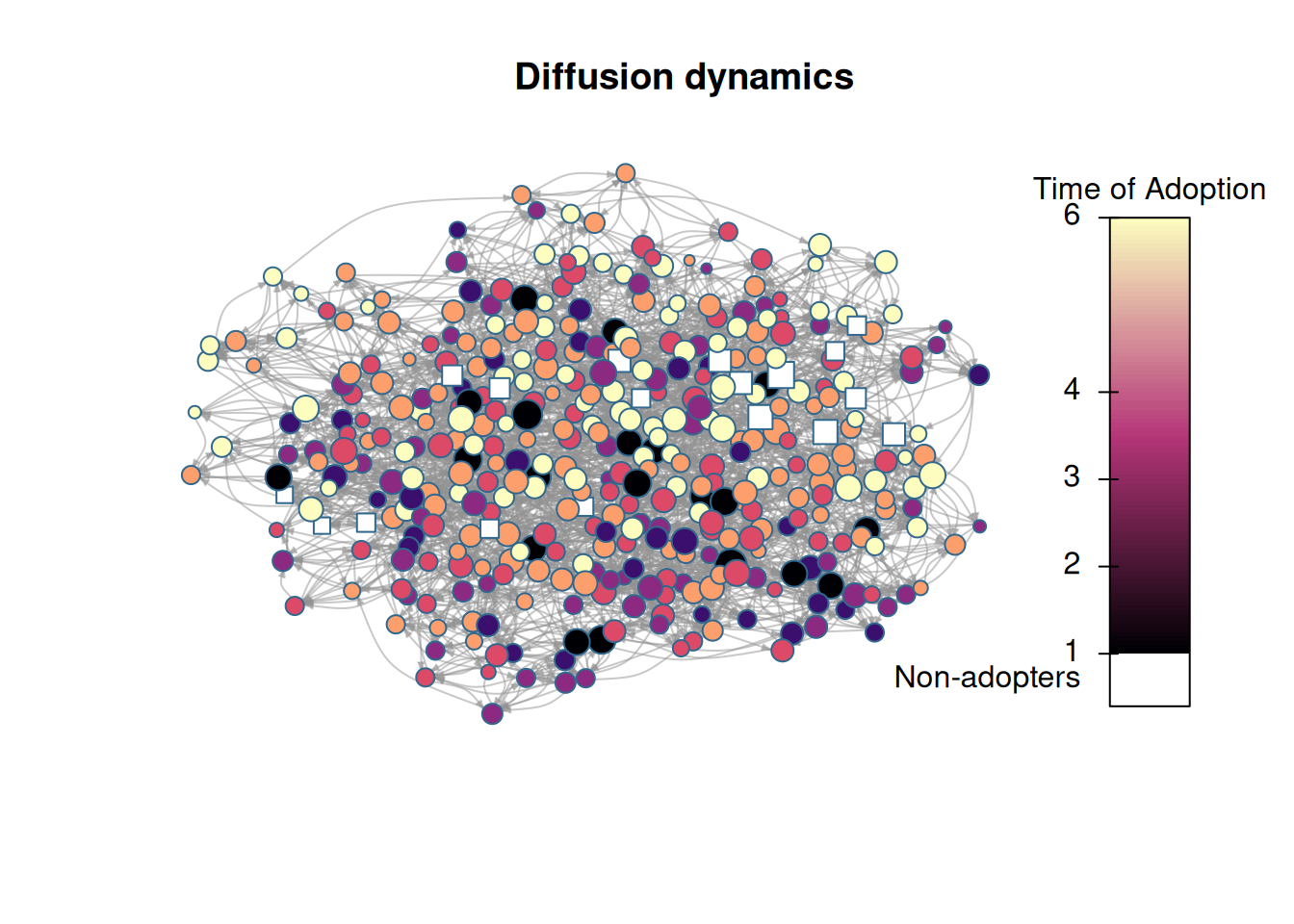
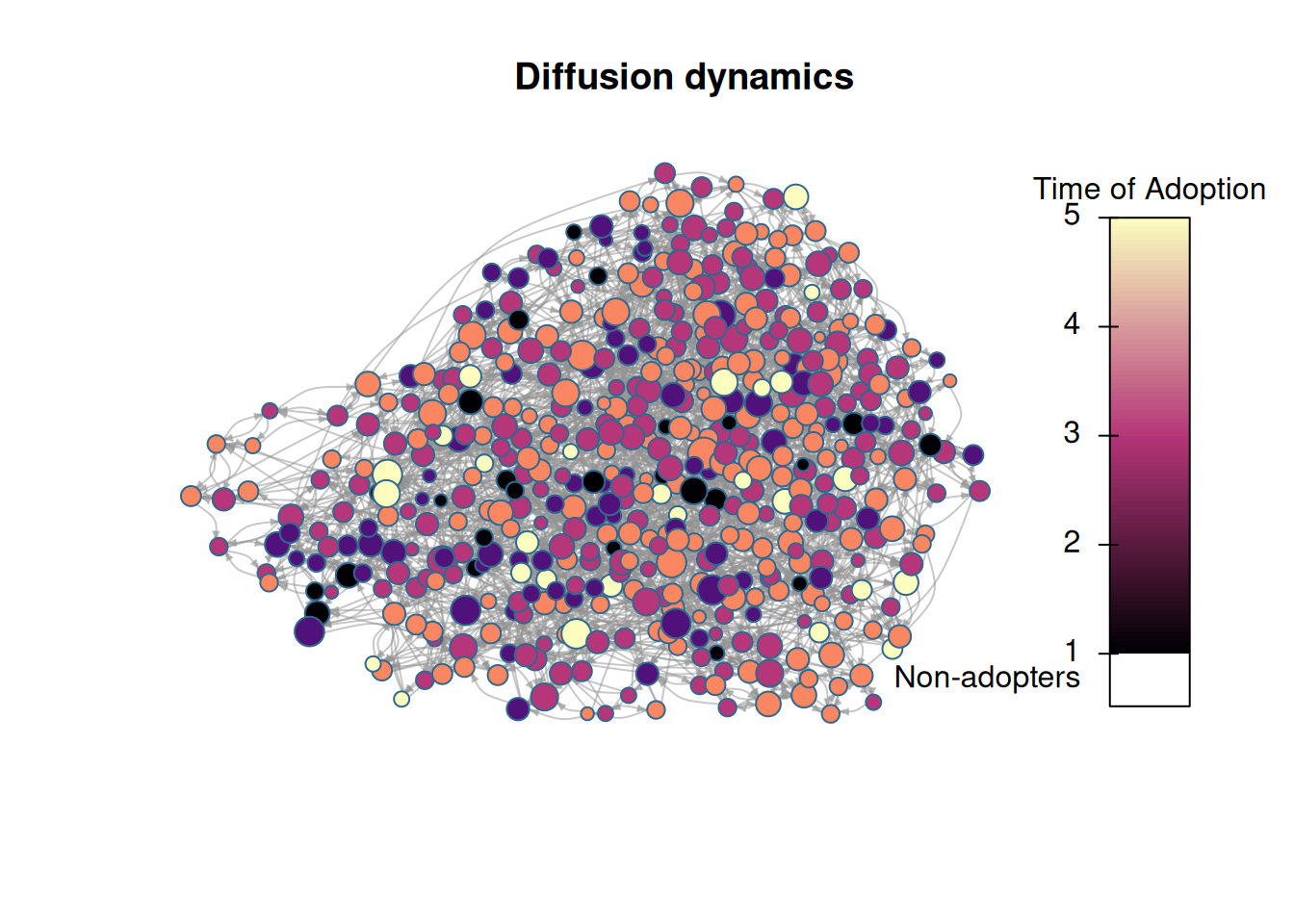
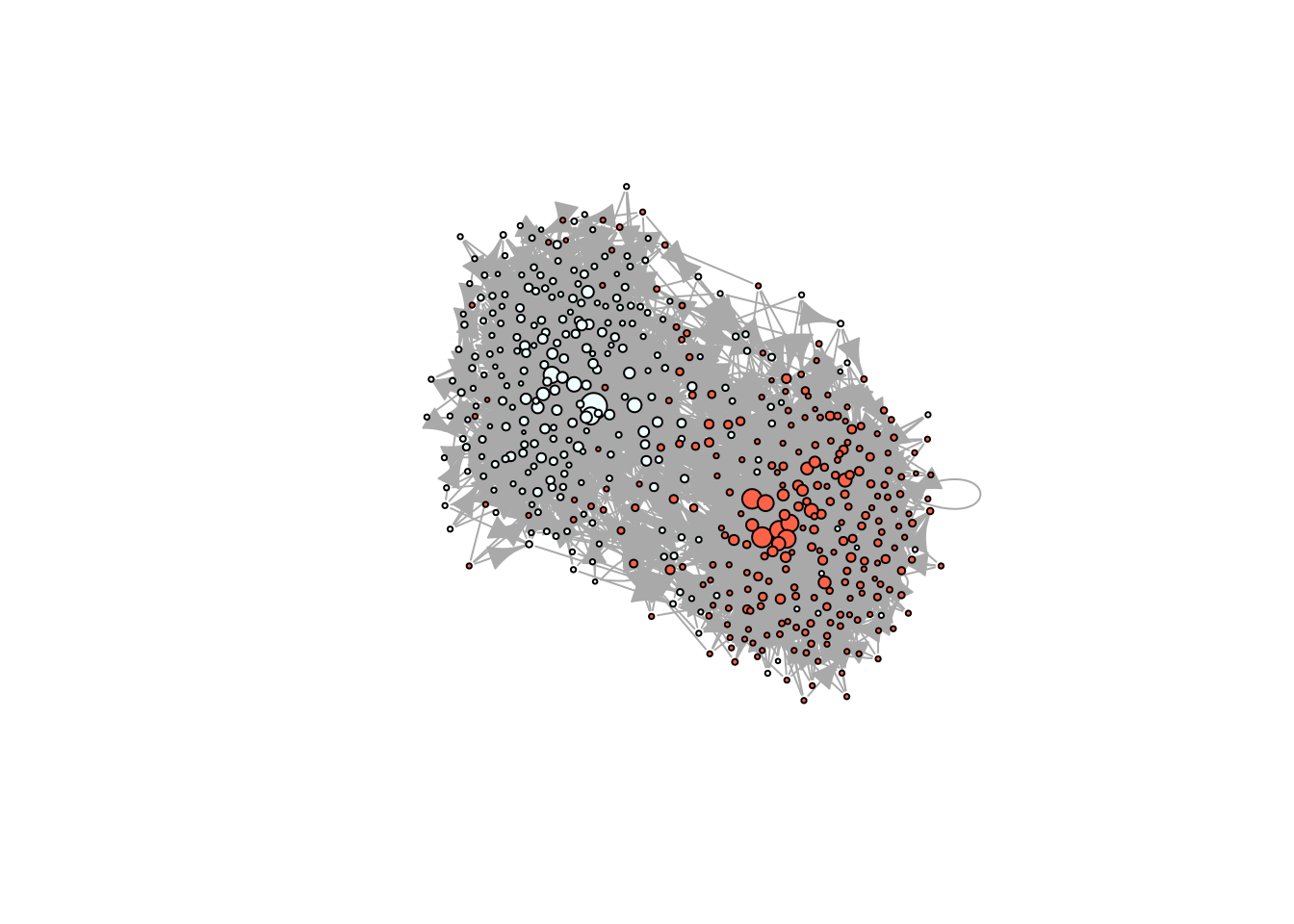
# We want to use igraph to compute layoutigdf <-diffnet_to_igraph(diffnet_rumor, slices=c(1,2))[[1]]pos <- igraph::layout_with_drl(igdf)plot_diffnet2(diffnet_rumor, vertex.size =dgr(diffnet_rumor)[,1], layout=pos)
# Simulating a scale-free homophilic networkset.seed(1231)X <-rep(c(1,1,1,1,1,0,0,0,0,0), 50)net <-rgraph_ba(t =499, m=4, eta = X)# Taking a look in igraphig <- igraph::graph_from_adjacency_matrix(net)plot(ig, vertex.color =c("azure", "tomato")[X+1], vertex.label =NA,vertex.size =sqrt(dgr(net)))
# Now, simulating a bunch of diffusion processesnsim <-500Lans_1and2 <-vector("list", nsim)set.seed(223)for (i in1:nsim) {# We just want the cum adopt count ans_1and2[[i]] <-cumulative_adopt_count(rdiffnet(seed.graph = net,t =10,threshold.dist =sample(1:2, 500L, TRUE),seed.nodes ="random",seed.p.adopt = .10,exposure.args =list(outgoing =FALSE, normalized =FALSE),rewire =FALSE ) )# Are we there yet?if (!(i %%50))message("Simulation ", i," of ", nsim, " done.")}## Simulation 50 of 500 done.## Simulation 100 of 500 done.## Simulation 150 of 500 done.## Simulation 200 of 500 done.## Simulation 250 of 500 done.## Simulation 300 of 500 done.## Simulation 350 of 500 done.## Simulation 400 of 500 done.## Simulation 450 of 500 done.## Simulation 500 of 500 done.# Extracting propans_1and2 <-do.call(rbind, lapply(ans_1and2, "[", i="prop", j=))ans_2and3 <-vector("list", nsim)set.seed(223)for (i in1:nsim) {# We just want the cum adopt count ans_2and3[[i]] <-cumulative_adopt_count(rdiffnet(seed.graph = net,t =10,threshold.dist =sample(2:3, 500L, TRUE),seed.nodes ="random",seed.p.adopt = .10,exposure.args =list(outgoing =FALSE, normalized =FALSE),rewire =FALSE ) )# Are we there yet?if (!(i %%50))message("Simulation ", i," of ", nsim, " done.")}## Simulation 50 of 500 done.## Simulation 100 of 500 done.## Simulation 150 of 500 done.## Simulation 200 of 500 done.## Simulation 250 of 500 done.## Simulation 300 of 500 done.## Simulation 350 of 500 done.## Simulation 400 of 500 done.## Simulation 450 of 500 done.## Simulation 500 of 500 done.ans_2and3 <-do.call(rbind, lapply(ans_2and3, "[", i="prop", j=))
Podemos simplificar usando la función rdiffnet_multiple. Las siguientes líneas de código logran lo mismo que el código anterior evitando el bucle for (desde la perspectiva del usuario). Además de los parámetros usuales pasados a rdiffnet, la función rdiffnet_multiple requiere R (número de repeticiones/simulaciones), y statistic (una función que devuelve la estadística de interés). Opcionalmente, el usuario puede elegir especificar el número de clusters para ejecutarlo en paralelo (múltiples CPUs):
ans_1and3 <-rdiffnet_multiple(# Num of simR = nsim,# Statisticstatistic =function(d) cumulative_adopt_count(d)["prop",], seed.graph = net,t =10,threshold.dist =sample(1:3, 500, TRUE),seed.nodes ="random",seed.p.adopt = .1,rewire =FALSE,exposure.args =list(outgoing=FALSE, normalized=FALSE),# Running on 4 coresncpus =4L )
Dados los siguientes tipos de redes: Mundo pequeño, Libre de escala, Bernoulli, ¿qué conjunto de n iniciadores maximiza la difusión?
Inferencia estadística
I de Moran
La I de Moran prueba la autocorrelación espacial.
netdiffuseR implementa la prueba en moran, que es adecuada para matrices dispersas.
Podemos usar la I de Moran como una primera mirada para ver si algo está pasando: ya sea influencia u homofilia.
Usando geodésicas
Un enfoque es usar la matriz geodésica (longitud de camino más corto) para considerar influencia indirecta.
netdiffuseR tiene una función para hacerlo, la función approx_geodesic, que, usando potencias de grafo, calcula el camino más corto hasta n pasos. Esto podría ser más rápido (si solo te importa hasta n pasos) que igraph o sns:
El método summary.diffnet ya ejecuta Moran para ti. Lo que pasa bajo el capó es:
# For each time point we compute the geodesic distances matrixW <-approx_geodesic(medInnovationsDiffNet$graph[[1]])# We get the element-wise inverseW@x <-1/W@x# And then compute moranmoran(medInnovationsDiffNet$cumadopt[,1], W)
Por ejemplo, si el tiempo de adopción es independiente de la estructura de la red, entonces el nivel de umbral promedio será independiente de la estructura de red también.
Otra manera de ver esto es que la prueba nos permitirá ver qué tan probable es tener esta combinación de estructura de red y umbral de red (si es poco común, entonces decimos que el modelo de difusión es altamente probable)
Ejemplo TOA no aleatorio
Para usar esta prueba, netdiffuseR tiene la función struct_test.
Simula redes con la misma densidad, y calcula una estadística particular cada vez, generando una EDF (Función de Distribución Empírica) bajo la hipótesis Nula (valores p).
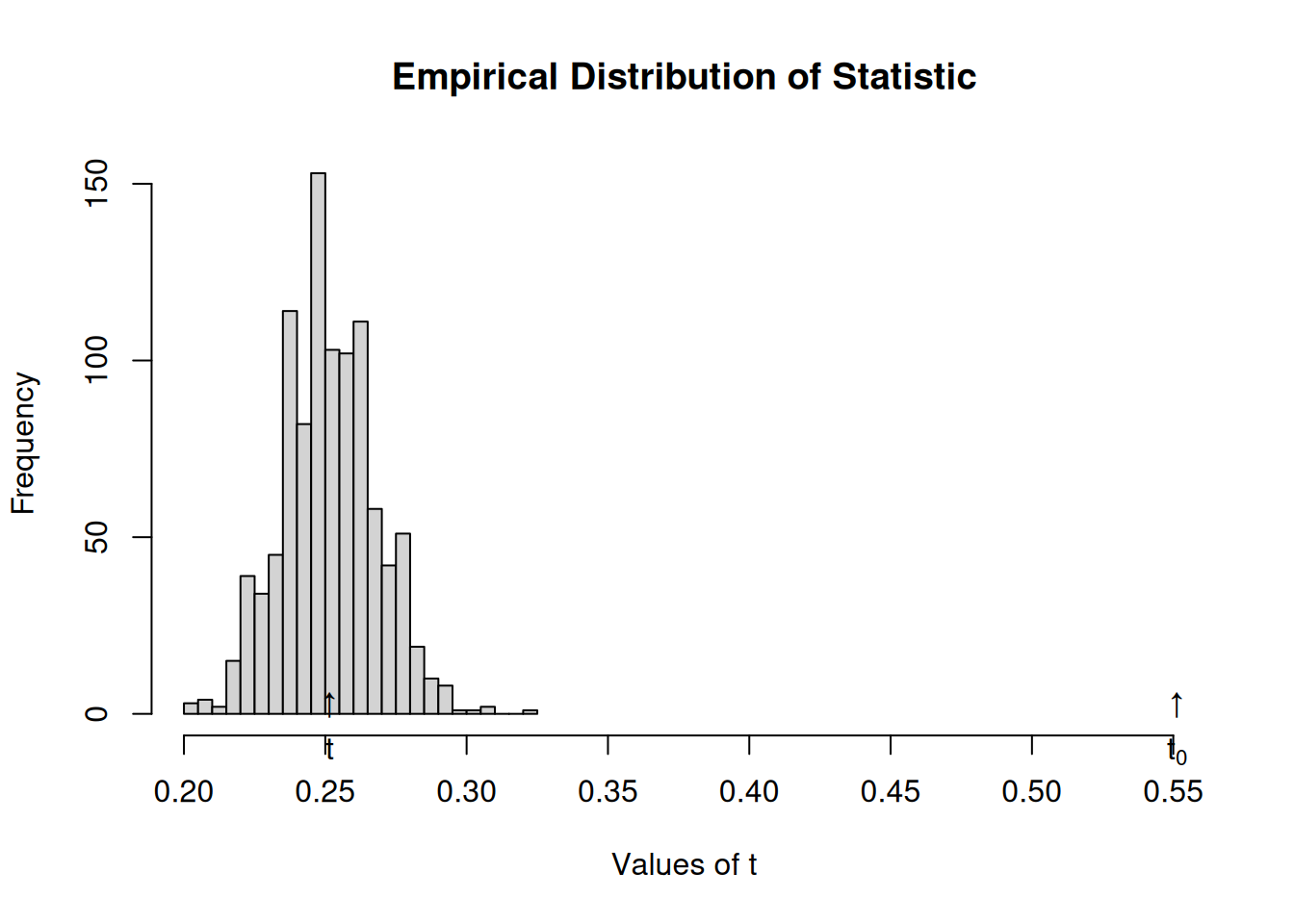
# Simulating networkset.seed(1123)net <-rdiffnet(n=500, t=10, seed.graph ="small-world")# Running the testtest <-struct_test(graph = net, statistic =function(x) mean(threshold(x), na.rm =TRUE),R =1e3,ncpus=4, parallel="multicore" )# See the outputtest
Structure dependence test
# Simulations : 1,000
# nodes : 500
# of time periods : 10
--------------------------------------------------------------------------------
H0: E[beta(Y,G)|G] - E[beta(Y,G)] = 0 (no structure dependency)
observed expected p.val
0.5513 0.2518 0.0000
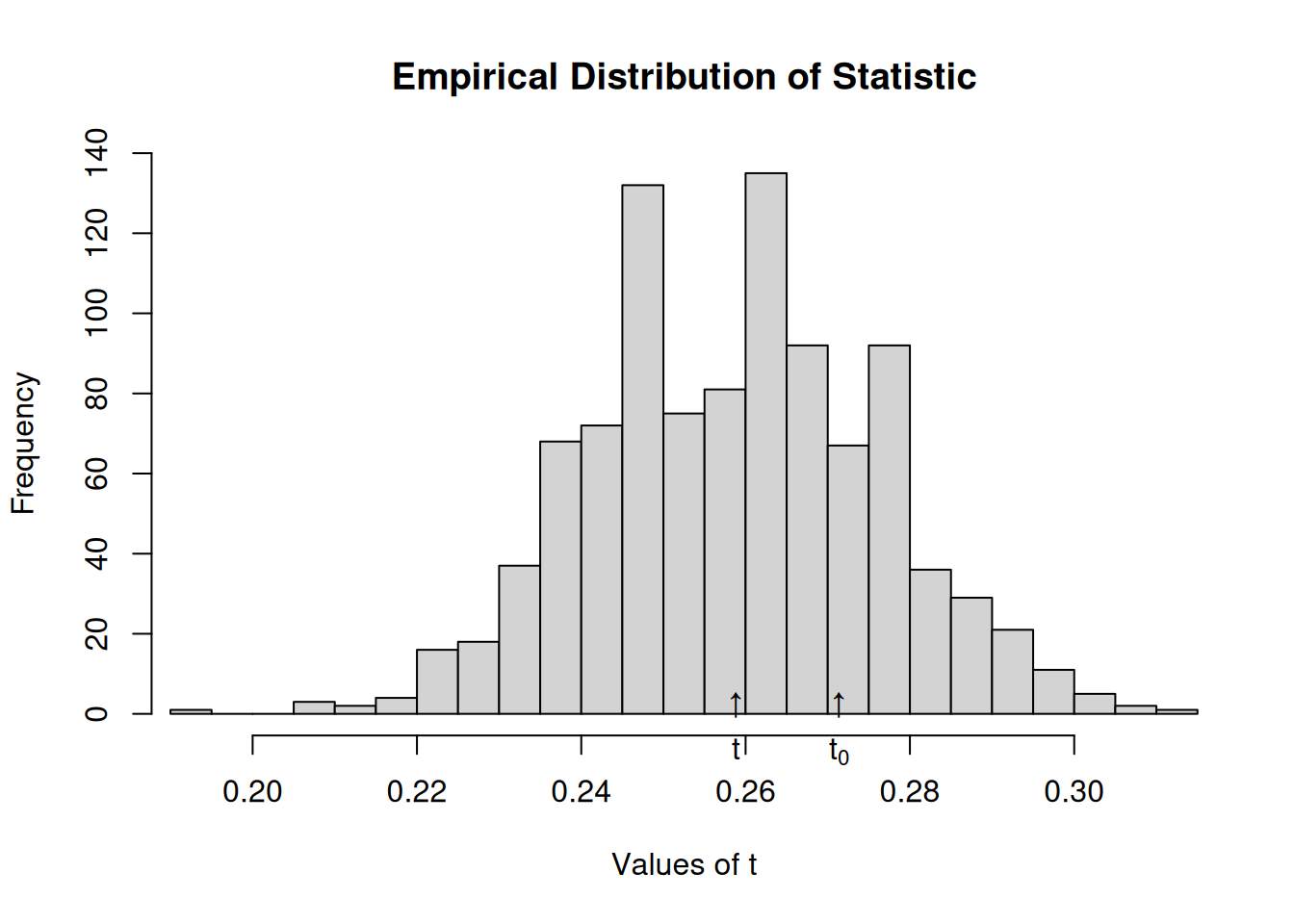
Ahora mezclamos tiempos de adopción, para que sea aleatorio
# Resetting TOAs (now will be completely random)diffnet.toa(net) <-sample(diffnet.toa(net), nnodes(net), TRUE)# Running the testtest <-struct_test(graph = net, statistic =function(x) mean(threshold(x), na.rm =TRUE),R =1e3,ncpus=4, parallel="multicore" )# See the outputtest
Structure dependence test
# Simulations : 1,000
# nodes : 500
# of time periods : 10
--------------------------------------------------------------------------------
H0: E[beta(Y,G)|G] - E[beta(Y,G)] = 0 (no structure dependency)
observed expected p.val
0.2714 0.2583 0.3880
Análisis de regresión
En análisis de regresión, queremos ver si la exposición, una vez que controlamos por otras covariables, tuvo algún efecto en adoptar un comportamiento.
El gran problema es cuando tenemos una variable latente que co-determina tanto red como comportamiento.
El análisis de regresión será genéricamente sesgado A menos que podamos controlar por esa variable.
Por otro lado, si puedes afirmar que tal variable no existe o que realmente puedes controlar por ella, entonces tenemos dos opciones: modelos de exposición retrasada o modelos de exposición contemporánea. Nos enfocaremos en los primeros.
Modelos de exposición retrasada
En este tipo de modelo, usualmente tenemos lo siguiente
Desafortunadamente, dado que y_t está en ambos lados de la ecuación, estos modelos no pueden ser ajustados usando una regresión probit o logit estándar.
Dos alternativas para resolver esto:
Usando Probit de Variables Instrumentales (ivprobit tanto en R como en Stata)
Usar un Probit Autorregresivo Espacial (SAR) (SpatialProbit y ProbitSpatial en R).
Calcula la I de Moran como lo hace la función summary.diffnet. Para hacerlo, necesitarás usar la función toa_mat (que calcula la matriz de adopción acumulativa), y approx_geodesic (que calcula la matriz geodésica). (ver ?summary.diffnet para más detalles).
Lee los datos como objeto diffnet, y ajusta el siguiente modelo logit adopt = Exposure*\gamma + Measure*\beta + \varepsilon. ¿Qué pasa si excluyes los efectos fijos de tiempo?