Esta versión del capítulo fue traducida de manera automática utilizando IA. El capítulo aún no ha sido revisado por un humano.
R (R Core Team 2024) es un lenguaje de programación orientado a la computación estadística. R se ha convertido en el lenguaje de programación de facto en la comunidad de redes sociales debido al gran número de paquetes disponibles para análisis de redes. Los paquetes de R son colecciones de funciones, datos y documentación que extienden R. Un buen libro de referencia tanto para usuarios novatos como avanzados es “The Art of R programming”Matloff (2011)1.
Obtener R
Puedes obtener R desde el sitio web de Comprehensive R Archive Network [CRAN] (enlace). CRAN es una red de servidores en todo el mundo que almacenan versiones idénticas y actualizadas de código y documentación para R. El sitio web de CRAN también tiene mucha información sobre R, incluyendo manuales, FAQs y listas de correo.
Aunque R viene con una Interfaz Gráfica de Usuario [GUI], recomiendo obtener una alternativa como RStudio o VSCode. RStudio y VSCode son excelentes compañeros para programar en R. Mientras que RStudio es más común entre los usuarios de R, VSCode es un IDE de propósito más general que puede usarse para muchos otros lenguajes de programación, incluyendo Python y C++.
Cómo instalar paquetes
Hoy en día, hay dos formas de instalar paquetes de R (que yo conozca), ya sea usando install.packages, que es una función que viene con R, o usando el paquete de R devtools para instalar un paquete desde algún repositorio remoto que no sea CRAN, aquí hay algunos ejemplos:
# Esto instalará el paquete igraph desde CRAN>install.packages("netdiffuseR")# ¡Esto instalará la versión más reciente desde el repositorio GitHub del proyecto!> devtools::install_github("USCCANA/netdiffuseR")
El primero, usando install.packages, instala la versión de CRAN de netdiffuseR, mientras que la línea de código instala cualquier versión que esté publicada en https://github.com/USCCANA/netdiffuseR, que usualmente se llama la versión de desarrollo.
En algunos casos, los usuarios pueden querer/necesitar instalar paquetes desde la línea de comandos ya que algunos paquetes necesitan configuración extra para ser instalados. Pero no necesitaremos ver eso ahora.
Una Introducción suave Rápida y Sucia a R
Algunas tareas comunes en R
Obtener ayuda (y leer el manual) es LO MÁS IMPORTANTE que deberías saber. Por ejemplo, si quieres leer el manual (archivo de ayuda) de la función read.csv, puedes escribir cualquiera de estos:
En R, puedes crear nuevos objetos usando el operador de asignación (<-) o el signo igual =, por ejemplo, los siguientes dos son equivalentes: r a <- 1 a = 1 Históricamente, el operador de asignación es el más comúnmente usado.
R tiene varios tipos de objetos. Las estructuras más básicas en R son vectors, matrix, list, data.frame. Aquí hay un ejemplo de creación de varios de estos (cada línea está encerrada con paréntesis para que R imprima el elemento resultante):
(a_vector <-1:9)
[1] 1 2 3 4 5 6 7 8 9
(another_vect <-c(1, 2, 3, 4, 5, 6, 7, 8, 9))
[1] 1 2 3 4 5 6 7 8 9
(a_string_vec <-c("I", "like", "netdiffuseR"))
[1] "I" "like" "netdiffuseR"
(a_matrix <-matrix(a_vector, ncol =3))
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
# Las matrices también pueden ser de strings(a_string_mat <-matrix(letters[1:9], ncol=3))
# Los data frames pueden tener múltiples tipos de elementos; es# una colección de listas(a_data_frame <-data.frame(x =1:10, y = letters[1:10]))
x y
1 1 a
2 2 b
3 3 c
4 4 d
5 5 e
6 6 f
7 7 g
8 8 h
9 9 i
10 10 j
Dependiendo del tipo de objeto, podemos acceder a sus componentes usando indexación:
# Primeros 3 elementosa_vector[1:3]
[1] 1 2 3
# Tercer elementoa_string_vec[3]
[1] "netdiffuseR"
# Una sub matriza_matrix[1:2, 1:2]
[,1] [,2]
[1,] 1 4
[2,] 2 5
# Tercera columnaa_matrix[,3]
[1] 7 8 9
# Tercera filaa_matrix[3,]
[1] 3 6 9
# Primeros 6 elementos de la matriz. R almacena matrices# por columna.a_string_mat[1:6]
[1] "a" "b" "c" "d" "e" "f"
# Estos tres son equivalentesanother_list[[1]]
[1] 1 2 3 4 5 6 7 8 9
another_list$my_vec
[1] 1 2 3 4 5 6 7 8 9
another_list[["my_vec"]]
[1] 1 2 3 4 5 6 7 8 9
# Los data frames son como listasa_data_frame[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
a_data_frame[,1]
[1] 1 2 3 4 5 6 7 8 9 10
a_data_frame[["x"]]
[1] 1 2 3 4 5 6 7 8 9 10
a_data_frame$x
[1] 1 2 3 4 5 6 7 8 9 10
Declaraciones de flujo de control
# El bucle for de toda la vidafor (i in1:10) {print(paste("Estoy en el paso", i, "/", 10))}
[1] "Estoy en el paso 1 / 10"
[1] "Estoy en el paso 2 / 10"
[1] "Estoy en el paso 3 / 10"
[1] "Estoy en el paso 4 / 10"
[1] "Estoy en el paso 5 / 10"
[1] "Estoy en el paso 6 / 10"
[1] "Estoy en el paso 7 / 10"
[1] "Estoy en el paso 8 / 10"
[1] "Estoy en el paso 9 / 10"
[1] "Estoy en el paso 10 / 10"
# Un buen ifelsefor (i in1:10) {if (i %%2) # Operando móduloprint(paste("Estoy en el paso", i, "/", 10, "(y soy impar)"))elseprint(paste("Estoy en el paso", i, "/", 10, "(y soy par)"))}
[1] "Estoy en el paso 1 / 10 (y soy impar)"
[1] "Estoy en el paso 2 / 10 (y soy par)"
[1] "Estoy en el paso 3 / 10 (y soy impar)"
[1] "Estoy en el paso 4 / 10 (y soy par)"
[1] "Estoy en el paso 5 / 10 (y soy impar)"
[1] "Estoy en el paso 6 / 10 (y soy par)"
[1] "Estoy en el paso 7 / 10 (y soy impar)"
[1] "Estoy en el paso 8 / 10 (y soy par)"
[1] "Estoy en el paso 9 / 10 (y soy impar)"
[1] "Estoy en el paso 10 / 10 (y soy par)"
# Un whilei <-10while (i >0) {print(paste("Estoy en el paso", i, "/", 10)) i <- i -1}
[1] "Estoy en el paso 10 / 10"
[1] "Estoy en el paso 9 / 10"
[1] "Estoy en el paso 8 / 10"
[1] "Estoy en el paso 7 / 10"
[1] "Estoy en el paso 6 / 10"
[1] "Estoy en el paso 5 / 10"
[1] "Estoy en el paso 4 / 10"
[1] "Estoy en el paso 3 / 10"
[1] "Estoy en el paso 2 / 10"
[1] "Estoy en el paso 1 / 10"
R tiene un conjunto convincente de funciones de generación de números pseudo-aleatorios. En general, las funciones de distribución tienen la siguiente estructura de nombres:
Generación de Números Aleatorios: r[nombre-de-la-distribución], ej., rnorm para normal, runif para uniforme.
Función de densidad: d[nombre-de-la-distribución], ej. dnorm para normal, dunif para uniforme.
Función de Distribución Acumulativa (CDF): p[nombre-de-la-distribución], ej., pnorm para normal, punif para uniforme.
Función inversa (cuantil): q[nombre-de-la-distribución], ej. qnorm para la normal, qunif para la uniforme.
Aquí hay algunos ejemplos:
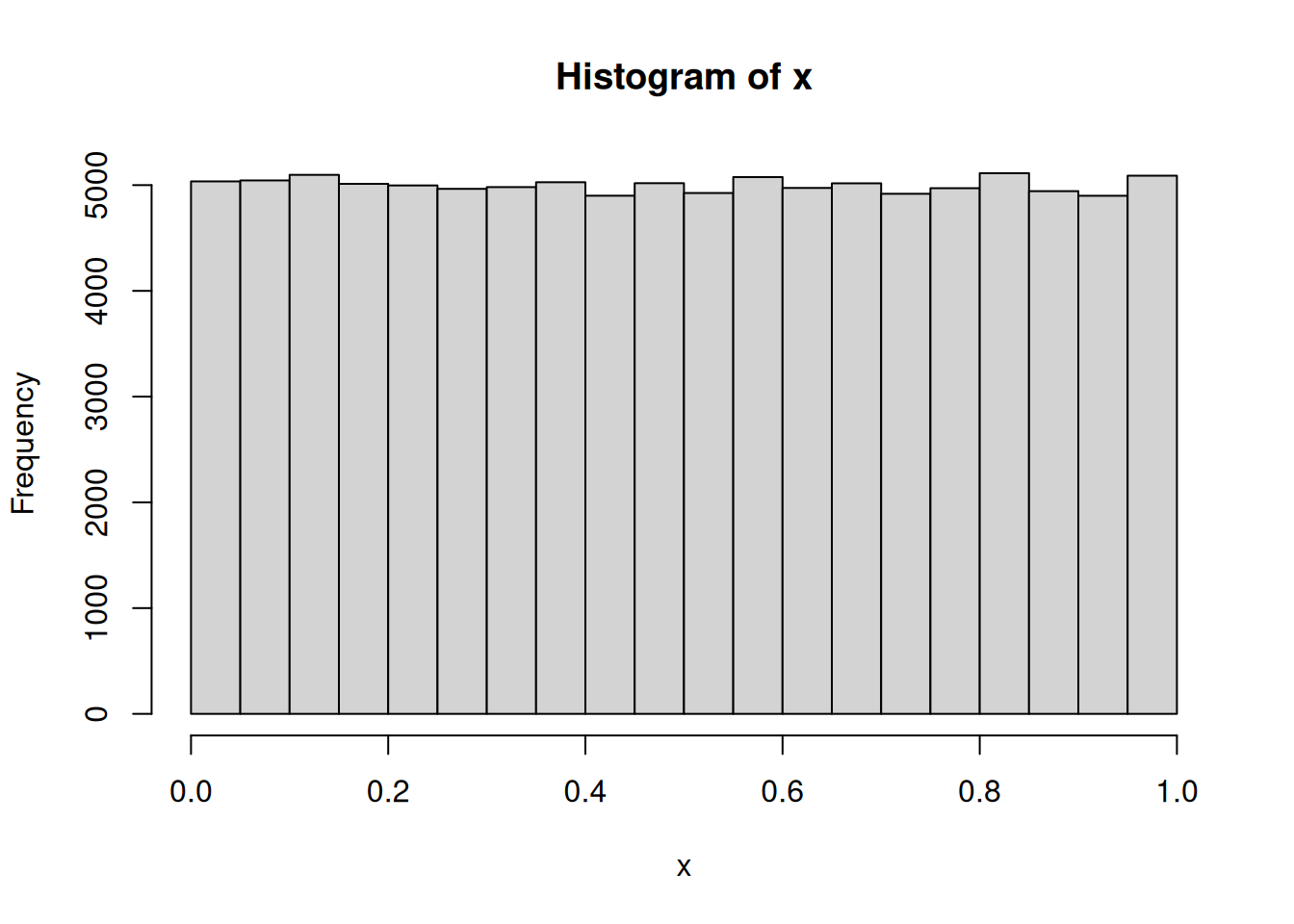
# Para asegurar reproducibilidadset.seed(1231)# 100,000 números Unif(0,1)x <-runif(1e5)hist(x)
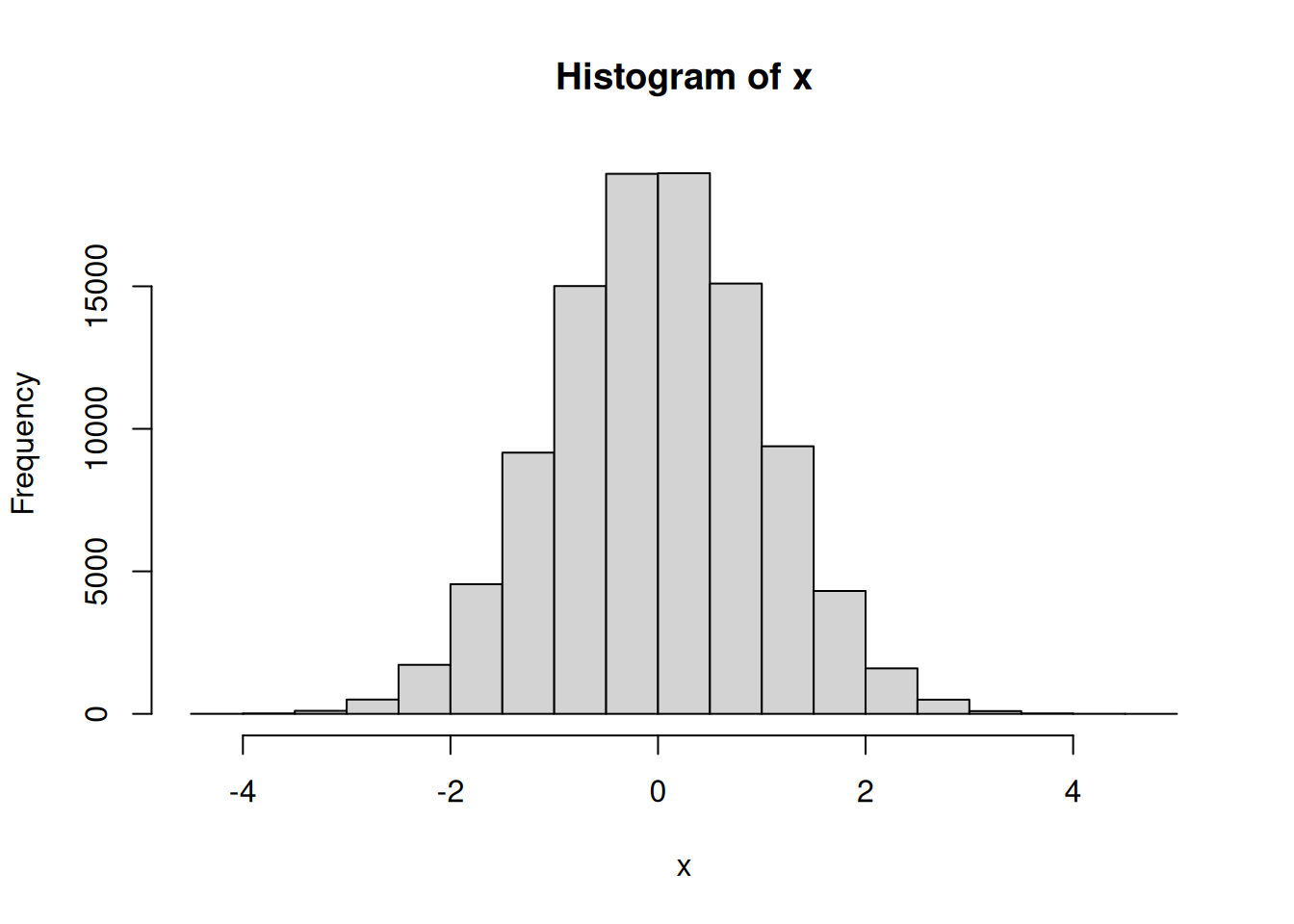
# 100,000 números N(0,1)x <-rnorm(1e5)hist(x)
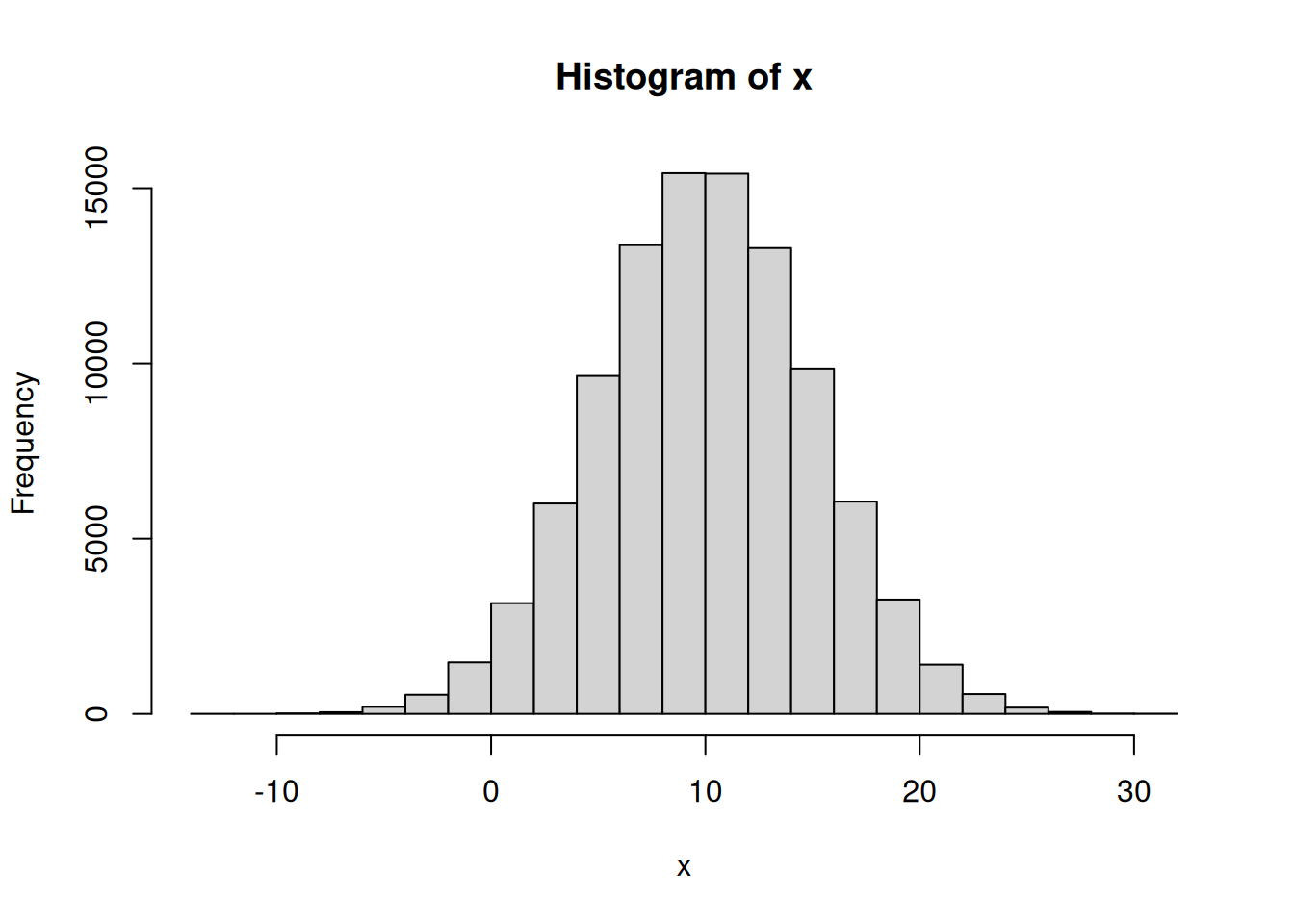
# 100,000 números N(10,25)x <-rnorm(1e5, mean =10, sd =5)hist(x)
Matloff, Norman. 2011. The Art of r Programming: A Tour of Statistical Software Design. No Starch Press.
R Core Team. 2024. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Aquí una versión pdf gratuita distribuida por el autor.↩︎