Esta versión del capítulo fue traducida de manera automática utilizando IA. El capítulo aún no ha sido revisado por un humano.
Este capítulo proporciona un ejemplo de principio a fin para procesar datos tipo encuesta en R. El capítulo presenta el conjunto de datos del Estudio de Redes Sociales [SNS]. Puedes descargar los datos para este capítulo aquí, y el libro de códigos para los datos proporcionados aquí está en el apéndice.
Los objetivos para este capítulo son:
Leer los datos en R.
Crear una red con ellos.
Calcular estadísticas descriptivas.
Visualizar la red.
Preprocesamiento de datos
Leyendo los datos en R
R tiene varias formas de leer datos. Tus datos pueden ser archivos de texto plano como CSV, delimitados por tabulaciones, o especificados por ancho de columna. Para leer datos de texto plano, puedes usar el paquete readr(Wickham, Hester, and Bryan 2024). En el caso de archivos binarios, como archivos de Stata, Octave, o SPSS, puedes usar el paquete de R foreign(R Core Team 2023). Si tus datos están formateados como hojas de cálculo de Microsoft, el paquete de R readxl(Wickham and Bryan 2023) es la alternativa a usar. En nuestro caso, los datos para esta sesión están en formato Stata:
library(foreign)# Leyendo los datosdat <- foreign::read.dta("03-sns.dta")# Echando un vistazo a las primeras 5 columnas y 5 filas de los datosdat[1:5, 1:10]
photoid school hispanic female1 female2 female3 female4 grades1 grades2
1 1 111 1 NA NA 0 0 NA NA
2 2 111 1 0 NA NA 0 3.0 NA
3 7 111 0 1 1 1 1 5.0 4.5
4 13 111 1 1 1 1 1 2.5 2.5
5 14 111 1 1 1 1 NA 3.0 3.5
grades3
1 3.5
2 NA
3 4.0
4 2.5
5 3.5
Creando un id único para cada participante
Debemos crear un id único usando la escuela y el id de foto. Dado que ambas variables son numéricas, codificar el id es una buena forma de hacer esto. Por ejemplo, los últimos tres números son el photoid, y los primeros números son el id de la escuela. Para hacer esto, necesitamos tomar en cuenta el rango de las variables:
(photo_id_ran <-range(dat$photoid))
[1] 1 2074
Como la variable se extiende hasta 2074, necesitamos establecer las últimas 4 unidades de la variable para almacenar el photoid. Usaremos dplyr(Wickham et al. 2023) para crear esta variable y la llamaremos id:
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
# Creando la variabledat <- dat |>mutate(id = school*10000+ photoid)# Primeras filasdat |>head() |>select(school, photoid, id)
¡Vaya, qué pasó en las últimas líneas de código! ¿Qué es ese |>? Bueno, ese es el operador pipe1, y es una forma atractiva de escribir llamadas a funciones anidadas. En este caso, en lugar de escribir algo como:
Queremos construir una red social. Para eso, usamos una matriz de adyacencia o una lista de enlaces.
Cada individuo de los datos SNS nominó 19 amigos de la escuela. Usaremos esas nominaciones para crear la red social.
En este caso, crearemos la red coercionando el conjunto de datos en una lista de enlaces.
De encuesta a lista de enlaces
Comencemos cargando un par de paquetes útiles de R. Cargaremos tidyr(Wickham, Vaughan, and Girlich 2024) y stringr(Wickham 2023). Usaremos el primero, tidyr, para remodelar los datos. El segundo, stringr, nos ayudará a procesar cadenas usando expresiones regulares2.
library(tidyr)library(stringr)
Opcionalmente, podemos usar el tipo de objeto tibble, una alternativa al data.frame actual. Este objeto proporciona métodos más eficientes para matrices y marcos de datos.
dat <-as_tibble(dat)
Lo que me gusta de los tibbles es que cuando los imprimes en la consola, estos se ven bien:
dat
# A tibble: 2,164 × 100
photoid school hispanic female1 female2 female3 female4 grades1 grades2
<int> <int> <dbl> <int> <int> <int> <int> <dbl> <dbl>
1 1 111 1 NA NA 0 0 NA NA
2 2 111 1 0 NA NA 0 3 NA
3 7 111 0 1 1 1 1 5 4.5
4 13 111 1 1 1 1 1 2.5 2.5
5 14 111 1 1 1 1 NA 3 3.5
6 15 111 1 0 0 0 0 2.5 2.5
7 20 111 1 1 1 1 1 2.5 2.5
8 22 111 1 NA NA 0 0 NA NA
9 25 111 0 1 1 NA 1 4.5 3.5
10 27 111 1 0 NA 0 0 3.5 NA
# ℹ 2,154 more rows
# ℹ 91 more variables: grades3 <dbl>, grades4 <dbl>, eversmk1 <int>,
# eversmk2 <int>, eversmk3 <int>, eversmk4 <int>, everdrk1 <int>,
# everdrk2 <int>, everdrk3 <int>, everdrk4 <int>, home1 <int>, home2 <int>,
# home3 <int>, home4 <int>, sch_friend11 <int>, sch_friend12 <int>,
# sch_friend13 <int>, sch_friend14 <int>, sch_friend15 <int>,
# sch_friend16 <int>, sch_friend17 <int>, sch_friend18 <int>, …
# Tal vez demasiados pipes... ¡pero es genial!net <- dat |>select(id, school, starts_with("sch_friend")) |>gather(key ="varname", value ="content", -id, -school) |>filter(!is.na(content)) |>mutate(friendid = school*10000+ content,year =as.integer(str_extract(varname, "(?<=[a-z])[0-9]")),nnom =as.integer(str_extract(varname, "(?<=[a-z][0-9])[0-9]+")) )
Veamos esto paso a paso:
Primero, subconjuntamos los datos: Queremos mantener id, school, sch_friend*. Para este último, usamos la función starts_with (del paquete tidyselect). Este último nos permite seleccionar todas las variables que comienzan con la palabra “sch_friend”, lo que significa que sch_friend11, sch_friend12, ... serán seleccionadas.
dat |>select(id, school, starts_with("sch_friend"))
# A tibble: 2,164 × 78
id school sch_friend11 sch_friend12 sch_friend13 sch_friend14
<dbl> <int> <int> <int> <int> <int>
1 1110001 111 NA NA NA NA
2 1110002 111 424 423 426 289
3 1110007 111 629 505 NA NA
4 1110013 111 232 569 NA NA
5 1110014 111 582 134 41 592
6 1110015 111 26 488 81 138
7 1110020 111 528 NA 492 395
8 1110022 111 NA NA NA NA
9 1110025 111 135 185 553 84
10 1110027 111 346 168 559 5
# ℹ 2,154 more rows
# ℹ 72 more variables: sch_friend15 <int>, sch_friend16 <int>,
# sch_friend17 <int>, sch_friend18 <int>, sch_friend19 <int>,
# sch_friend110 <int>, sch_friend111 <int>, sch_friend112 <int>,
# sch_friend113 <int>, sch_friend114 <int>, sch_friend115 <int>,
# sch_friend116 <int>, sch_friend117 <int>, sch_friend118 <int>,
# sch_friend119 <int>, sch_friend21 <int>, sch_friend22 <int>, …
Luego, lo remodelamos a formato largo: Transponiendo todos los sch_friend* a formato largo. Hacemos esto usando la función gather (del paquete tidyr); una alternativa a la función reshape, que encuentro más fácil de usar. Veamos cómo funciona:
dat |>select(id, school, starts_with("sch_friend")) |>gather(key ="varname", value ="content", -id, -school)
En este caso, el parámetro key establece el nombre de la variable que contendrá el nombre de la variable que fue remodelada, mientras que value es el nombre de la variable que contendrá el contenido de los datos (por eso los nombré así). El bit -id, -school le dice a la función que “elimine” esas variables antes de remodelar. En otras palabras, “remodela todo excepto id y school.”
También, nota que pasamos de 2164 filas a 19 (nominaciones) * 2164 (sujetos) * 4 (ondas) = 164464 filas, como se esperaba.
Como los datos de nominación pueden estar vacíos para algunas celdas, necesitamos cuidar esos casos, los NAs, así que filtramos los datos:
dat |>select(id, school, starts_with("sch_friend")) |>gather(key ="varname", value ="content", -id, -school) |>filter(!is.na(content))
Y finalmente, creamos tres nuevas variables de este conjunto de datos: friendid,, year, y nom_num (número de nominación). Todo usando expresiones regulares:
dat |>select(id, school, starts_with("sch_friend")) |>gather(key ="varname", value ="content", -id, -school) |>filter(!is.na(content)) |>mutate(friendid = school*10000+ content,year =as.integer(str_extract(varname, "(?<=[a-z])[0-9]")),nnom =as.integer(str_extract(varname, "(?<=[a-z][0-9])[0-9]+")) )
La expresión regular (?<=[a-z]) coincide con una cadena precedida por cualquier letra de a a z. En contraste, la expresión [0-9] coincide con un solo número. Por lo tanto, de la cadena "sch_friend12", la expresión regular solo coincidirá con el 1, ya que es el único número seguido por una letra. La expresión (?<=[a-z][0-9]) coincide con una cadena precedida por una letra minúscula y un número de un dígito. Finalmente, la expresión [0-9]+ coincide con una cadena de números–así que podría ser más de uno. Por lo tanto, de la cadena "sch_friend12", obtendremos 2:
Y finalmente, la función as.integer coerciona el valor de retorno de la función str_extract de character a integer. Ahora que tenemos esta lista de enlaces, podemos crear un objeto igraph
Red igraph
Para coercionar la lista de enlaces en un objeto igraph, usaremos la función graph_from_data_frame en igraph (Csárdi et al. 2024). Esta función recibe los siguientes argumentos: un marco de datos donde las dos primeras columnas son “source” (ego) y “target” (alter), un indicador de si la red es dirigida o no, y un marco de datos opcional con vértices, en cuya primera columna debería contener los ids de vértice.
Usar el argumento opcional vertices es una buena práctica: Le dice a la función qué ids debería esperar. Usando el conjunto de datos original, crearemos un marco de datos con vértices de nombre:
vertex_attrs <- dat |>select(id, school, hispanic, female1, starts_with("eversmk"))
Ahora, usemos la función graph_from_data_frame para crear un objeto igraph:
Error in `graph_from_data_frame()`:
! Some vertex names in `d` are not listed in `vertices`
¡Ups! Parece que los individuos están nominando a otros estudiantes no incluidos en la encuesta. ¿Cómo resolver eso? Bueno, ¡todo depende de lo que necesites hacer! En este caso, iremos por la estrategia de elimínalos-silenciosamente-y-no-digas-nada:
library(igraph)ig_year1 <- net |>filter(year =="1") |># Línea extra, todas las nominaciones deben estar en ego también.filter(friendid %in% id) |>select(id, friendid, nnom) |>graph_from_data_frame(vertices = vertex_attrs )ig_year1
Así que tenemos nuestra red con 2164 nodos y 9514 enlaces. Los siguientes pasos: obtener algunas estadísticas descriptivas y visualizar nuestra red.
Estadísticas descriptivas de red
Aunque podríamos hacer todas las redes a la vez, en esta parte, nos enfocaremos en calcular algunas estadísticas de red para una sola escuela. Comenzamos por la escuela 111. La primera pregunta que deberías estar haciéndote ahora es, “¿cómo puedo obtener esa información del objeto igraph?.” Los atributos de vértices y enlaces se pueden acceder a través de las funciones V y E, respectivamente; además, podemos listar qué atributos de vértice/enlace están disponibles:
Tal como haríamos con marcos de datos, acceder a atributos de vértice se hace a través del operador signo de dólar $. Junto con la función V; por ejemplo, acceder a los primeros diez elementos de la variable hispanic se puede hacer de la siguiente manera:
V(ig_year1)$hispanic[1:10]
[1] 1 1 0 1 1 1 1 1 0 1
Ahora que sabes cómo acceder a atributos de vértice, podemos obtener la red correspondiente a la escuela 111 identificando qué vértices son parte de ella y pasar esa información a la función induced_subgraph:
# ¿Qué ids son de la escuela 111?school111ids <-which(V(ig_year1)$school ==111)# Creando un subgrafoig_year1_111 <-induced_subgraph(graph = ig_year1,vids = school111ids)
La función which en R devuelve un vector de índices indicando qué elementos pasan la prueba, devolviendo verdadero y falso, de lo contrario. En nuestro caso, resultará en un vector de índices de los vértices que tienen el atributo school igual a 111. Con el subgrafo, podemos calcular diferentes medidas de centralidad3 para cada vértice y almacenarlas en el objeto igraph mismo:
# Calculando medidas de centralidad para cada vérticeV(ig_year1_111)$indegree <-degree(ig_year1_111, mode ="in")V(ig_year1_111)$outdegree <-degree(ig_year1_111, mode ="out")V(ig_year1_111)$closeness <-closeness(ig_year1_111, mode ="total")V(ig_year1_111)$betweeness <-betweenness(ig_year1_111, normalized =TRUE)
Desde aquí, podemos volver a nuestros viejos hábitos y obtener el conjunto de atributos de vértice como un marco de datos para que podamos calcular algunas estadísticas de resumen sobre las medidas de centralidad que acabamos de obtener
# Extrayendo cada característica de vértice como un data.framestats <-as_data_frame(ig_year1_111, what ="vertices")# Calculando cuantiles para cada variablestats_degree <-with(stats, {cbind(indegree =quantile(indegree, c(.025, .5, .975), na.rm =TRUE),outdegree =quantile(outdegree, c(.025, .5, .975), na.rm =TRUE),closeness =quantile(closeness, c(.025, .5, .975), na.rm =TRUE),betweeness =quantile(betweeness, c(.025, .5, .975), na.rm =TRUE) )})stats_degree
La función with es algo similar a lo que dplyr nos permite hacer cuando queremos trabajar con el conjunto de datos pero sin mencionar su nombre cada vez que pedimos una variable. Sin usar la función with, lo anterior podría haberse hecho de la siguiente manera:
Para obtener una vista más agradable de esto, podemos usar una tabla que recuperé de ?triad_census. Además, podemos normalizar el objeto triadic por su suma en lugar de mirar conteos en bruto. De esa manera, obtenemos proporciones en su lugar4
A<->B, C, the graph with a mutual connection between two vertices.
0.01
021D
A<-B->C, the out-star.
0.01
021U
A->B<-C, the in-star.
0.02
021C
A->B->C, directed line.
0.01
111D
A<->B<-C.
0.01
111U
A<->B->C.
0.00
030T
A->B<-C, A->C.
0.00
030C
A<-B<-C, A->C.
0.00
201
A<->B<->C.
0.00
120D
A<-B->C, A<->C.
0.00
120U
A->B<-C, A<->C.
0.00
120C
A->B->C, A<->C.
0.00
210
A->B<->C, A<->C.
0.00
300
A<->B<->C, A<->C, the complete graph.
Graficando la red en igraph
Gráfico único
Echemos un vistazo a cómo se ve nuestra red cuando usamos los parámetros predeterminados en el método plot del objeto igraph:
plot(ig_year1)
Un gráfico de red no muy agradable. Esto es lo que obtenemos con los parámetros predeterminados en igraph.
No muy agradable, ¿verdad? Un par de cosas con este gráfico:
Estamos viendo todas las escuelas simultáneamente, lo que no tiene sentido. Así que, en lugar de graficar ig_year1, nos enfocaremos en ig_year1_111.
Todos los vértices tienen el mismo tamaño y se están solapando. En lugar de usar el tamaño predeterminado, dimensionaremos los vértices por indegree usando la función degree y pasando el vector de grados a vertex.size.5
Dado el número de vértices en estas redes, las etiquetas no son útiles aquí. Así que las eliminaremos estableciendo vertex.label = NA. Además, reduciremos el tamaño de la punta de las flechas estableciendo edge.arrow.size = 0.25.
Y finalmente, estableceremos el color de cada vértice para que sea una función de si el individuo es hispano o no. Para esta última parte necesitamos ir un poco más de programación:
La primera línea agregó uno a todos los valores no NA para que los 0s (no hispanos) se convirtieran en 1s y los 1s (hispanos) se convirtieran en 2s.
La segunda línea reemplazó todos los NAs con el número tres para que nuestro vector col_hispanic ahora vaya de uno a tres sin NAs en él.
En la última línea, creamos un vector de colores. Esencialmente, lo que estamos haciendo aquí es decirle a R que cree un vector de longitud length(col_hispanic) seleccionando elementos por índice del vector c("steelblue", "tomato", "white"). De esta manera, si, por ejemplo, el primer elemento del vector col_hispanic fuera un 3, nuestro nuevo vector de colores tendría un "white" en él.
Para asegurarnos de que sabemos que estamos en lo correcto, imprimamos los primeros 10 elementos de nuestro nuevo vector de colores junto con la columna original hispanic:
Con nuestro agradable vector de colores, ahora podemos pasarlo a plot.igraph (que llamamos implícitamente simplemente llamando plot), a través del argumento vertex.color:
¡Agradable! Así que se ve mejor. El único problema es que tenemos muchos aislados. Intentemos de nuevo dibujando el mismo gráfico sin aislados. Para hacer eso, necesitamos filtrar el grafo, para lo cual usaremos la función induced_subgraph
# ¿Qué vértices no son aislados?which_ids <-which(degree(ig_year1_111, mode ="total") >0)# Obteniendo el subgrafoig_year1_111_sub <-induced_subgraph(ig_year1_111, which_ids)# Necesitamos obtener el mismo subconjunto en col_hispaniccol_hispanic <- col_hispanic[which_ids]
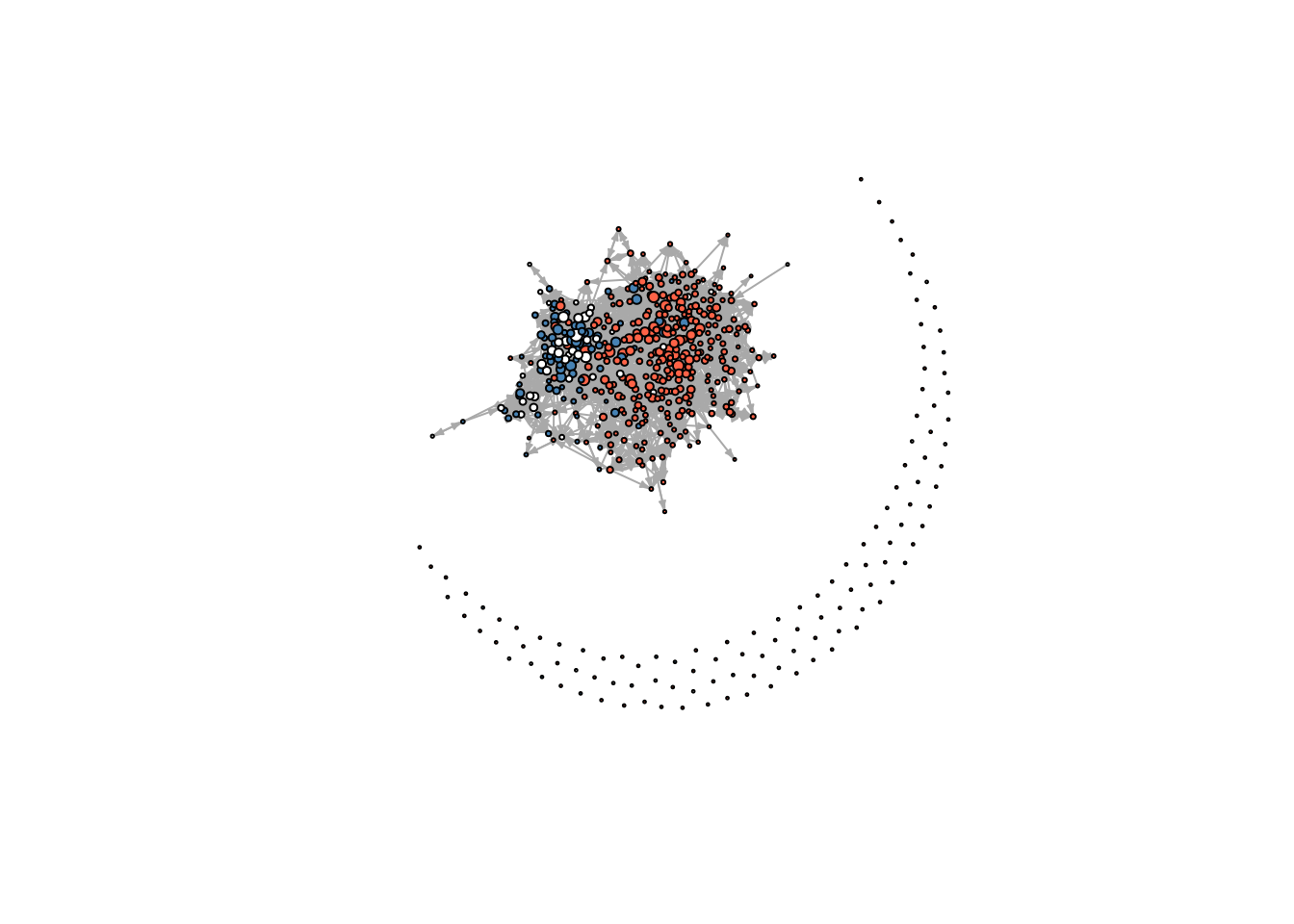
Red de amigos en tiempo 1 para la escuela 111. El grafo excluye aislados.
¡Ahora eso está mejor! Un patrón interesante que surge es que los individuos parecen agruparse por si son hispanos o no.
Podemos escribir esto como una función para evitar copiar y pegar el código n veces (suponiendo que queremos crear un gráfico similar a este n veces). Hacemos esto último en la siguiente subsección.
Múltiples gráficos
Cuando te estás repitiendo repetidamente, es una buena idea escribir una secuencia de comandos como una función. En este caso, dado que ejecutaremos el mismo tipo de gráfico para todas las escuelas/ondas, escribimos una función en la que las únicas cosas que cambian son: (a) el id de la escuela, y (b) el color de los nodos.
El myplot <- function([argumentos]) {[cuerpo de la función]} le dice a R que vamos a crear una función llamada myplot.
Declaramos cuatro argumentos específicos: net, schoolid, mindgr, y vcol. Estos son un objeto igraph, el id de la escuela, el grado mínimo que los vértices deben tener para ser incluidos en la figura, y el color de los vértices. Observa que, comparado con otros lenguajes de programación, R no requiere declarar los tipos de datos.
El objeto de puntos suspensivos, ..., es un objeto especial en R que nos permite pasar otros argumentos sin especificar cuáles. Si echas un vistazo al bit plot en el cuerpo de la función, verás que también agregamos .... Usamos los puntos suspensivos para pasar argumentos extra (diferentes de los que definimos explícitamente) directamente a plot. En la práctica, esto implica que podemos, por ejemplo, establecer el argumento edge.arrow.size al llamar myplot, ¡incluso aunque no lo incluimos en la definición de la función! (Ver ?dotsMethods en R para más detalles).
En las siguientes líneas de código, usando nuestra nueva función, graficaremos la red de cada escuela en el mismo dispositivo de graficado (ventana) con la ayuda de la función par, y agregaremos leyenda con el legend:
Las 5 escuelas en tiempo 1. Nuevamente, los grafos excluyen aislados.
Entonces, ¿qué pasó aquí?
oldpar <- par(no.readonly = TRUE) Esta línea almacena los parámetros actuales para graficar. Dado que vamos a estar cambiándolos, ¡más vale asegurarnos de que podemos volver!.
par(mfrow = c(2, 3), mai = rep(0, 4), oma=rep(0, 4)) Aquí estamos estableciendo varias cosas al mismo tiempo. mfrow especifica cuántas figuras se dibujarán, y en qué orden. En particular, estamos pidiendo al dispositivo de graficado que haga espacio para 2*3 = 6 figuras organizadas en dos filas y tres columnas dibujadas por fila.
mai especifica el tamaño de los márgenes en pulgadas, establecer todos los márgenes iguales a cero (que es lo que estamos haciendo ahora) da más espacio al gráfico. Lo mismo es cierto para oma. Ver ?par para más información.
myplot(ig_year1, ...) Esto es simplemente llamar nuestra función de graficado. La parte elegante de esto es que, dado que establecimos mfrow = c(2, 3), R se encarga de distribuir los gráficos en el dispositivo.
par(oldpar) Esta línea nos permite restaurar los parámetros de graficado.
Pruebas estadísticas
¿Está correlacionado el número de nominación con el indegree?
Hipótesis: Los individuos que, en promedio, están entre las primeras nominaciones de sus pares son más populares
# Obteniendo todos los datos en formato largoedgelist <-as_long_data_frame(ig_year1) |>as_tibble()# Calculando indegree (de nuevo) y número promedio de nominación# Incluir "En una escala del uno al cinco qué tan cerca te sientes"# También para amigos egocéntricos (A. Amigos)indeg_nom_cor <-group_by(edgelist, to, to_name, to_school) |>summarise(indeg =length(nnom),nom_avg =1/mean(nnom) ) |>rename(school = to_school )
`summarise()` has grouped output by 'to', 'to_name'. You can override using the
`.groups` argument.
# Usando correlación de Pearsonwith(indeg_nom_cor, cor.test(indeg, nom_avg))
Pearson's product-moment correlation
data: indeg and nom_avg
t = -12.254, df = 1559, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.3409964 -0.2504653
sample estimates:
cor
-0.2963965
save.image("03.rda")
Csárdi, Gábor, Tamás Nepusz, Vincent Traag, Szabolcs Horvát, Fabio Zanini, Daniel Noom, and Kirill Müller. 2024. igraph: Network Analysis and Visualization in r. https://doi.org/10.5281/zenodo.7682609.
Wickham, Hadley, Romain François, Lionel Henry, Kirill Müller, and Davis Vaughan. 2023. Dplyr: A Grammar of Data Manipulation. https://dplyr.tidyverse.org.
Wickham, Hadley, Jim Hester, and Jennifer Bryan. 2024. Readr: Read Rectangular Text Data. https://readr.tidyverse.org.
Wickham, Hadley, Davis Vaughan, and Maximilian Girlich. 2024. Tidyr: Tidy Messy Data. https://tidyr.tidyverse.org.
Por favor, consulta el archivo de ayuda ?'regular expression' en R. El paquete de R rex(Ushey, Hester, and Krzyzanowski 2021) es un compañero amigable para escribir expresiones regulares. También hay un complemento de RStudio ordenado (pero experimental) que puede ser muy útil para entender cómo funcionan las expresiones regulares, el complemento regexplain.↩︎
Para más información sobre las diferentes medidas de centralidad, por favor echa un vistazo al artículo “Centrality” en Wikipedia.↩︎
Durante nuestro taller, la Prof. De la Haye sugirió usar {n \choose 3} como una constante normalizadora. ¡Resulta que sum(triadic) = choose(n, 3)! Así que cualquier enfoque es correcto.↩︎
Descubrir cuál es el tamaño de vértice óptimo es un poco complicado. Sin ponerse demasiado técnico, no hay otra forma de obtener un tamaño de vértice agradable que no sea simplemente jugar con diferentes valores de él. Una solución agradable a esto es usar netdiffuseR::igraph_vertex_rescale que reescala los vértices para que estos mantengan su relación de aspecto a una proporción predefinida de la pantalla.↩︎